OpenAPI to MCP: How to Make Your API Agent-Ready
You already have an OpenAPI spec. Turning it into an MCP server is the easy part. Making it work well for AI agents is where most conversions fail. We've converted and tested real APIs — here's what breaks and how to fix it.
If you have a REST API with an OpenAPI spec, you're closer to having an agent-ready tool surface than you think. The conversion from OpenAPI operations to MCP tools is largely mechanical — several open-source tools will do it for you. But "converted" and "works well for agents" are very different things.
We built an OpenAPI-to-MCP ingestion pipeline and tested the output against real models. The conversion is straightforward. The optimization is where the real work happens — and where most publishers lose agent traffic without knowing it.
- ▸Naive 1:1 conversion fails — a 1,087-operation API becomes 1,087 tools, exceeding every model's capacity
- ▸Bundling reduces tool count 92% — tag-based bundling took GitHub from 570 to 41 tools with 74% token savings
- ▸Rewriting descriptions lifts task completion from 55% to 90% — raw OpenAPI descriptions are written for human developers, not AI agents
- ▸Auth must be handled server-side — agents cannot construct Authorization headers or distinguish free vs paid endpoints
- ▸Test across models before shipping — GPT-5.4 has a hard 128-tool cap; a surface that works on Claude may fail entirely on OpenAI
// finding 01
The conversion is simple. The problems aren't.
An OpenAPI spec defines operations: endpoints, methods, parameters, response schemas. An MCP tool surface defines tools: names, descriptions, input schemas. The mapping is direct:
GET /assets/{id} → tool: get_asset(id: string)
GET /assets → tool: list_assets(search?: string, limit?: int)
POST /orders → tool: create_order(symbol: string, side: string, ...)
Tools like Speakeasy, Stainless, and various open-source generators handle this conversion. Our pipeline parses OpenAPI 3.x, extracts operations, generates tool definitions, and creates a generic HTTP dispatcher. Mechanically, it works.
The problems start when agents try to use the result.
// finding 02
How many tools is too many for an MCP server?
This is the most common and most damaging conversion problem.
A typical REST API has dozens to hundreds of endpoints. A naive one-operation-per-tool conversion creates a tool surface that's unusable:
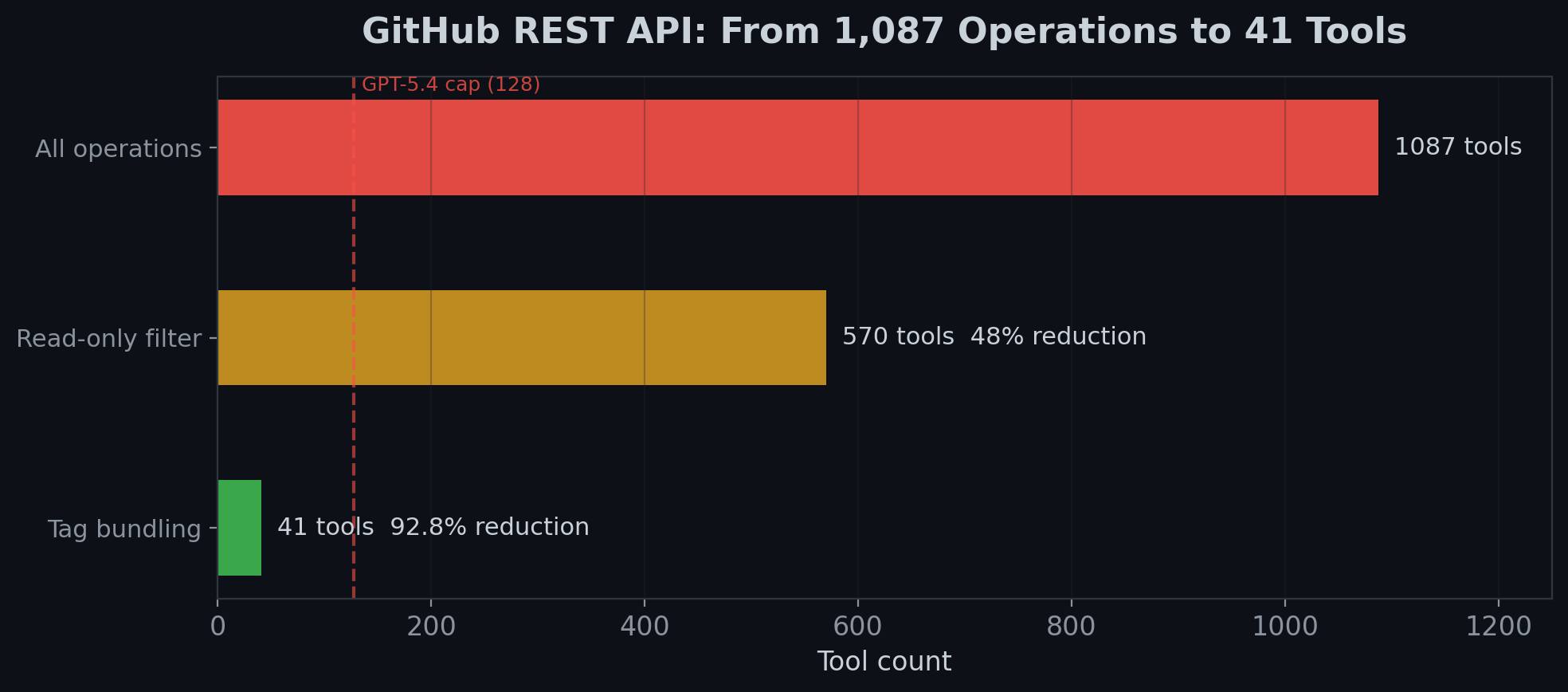
| API | Operations | Naive tool count | What happens |
|---|---|---|---|
| GitHub REST | 1,087 | 1,087 tools | Exceeds every model's capacity |
| GitHub (read-only) | 570 | 570 tools | Still exceeds GPT-5.4's 128-tool cap |
| GitHub (bundled) | — | 41 tools | All models can load and use it |
We tested this directly. The GitHub REST API has 1,087 operations. After filtering to read-only (570), the tool surface still couldn't be loaded by GPT-4o or GPT-5.4 — they have a hard cap at 128 tools, unchanged across model generations as of early 2026.
After bundling related operations by API tag (repositories, issues, pulls, etc.), the surface dropped to 41 tools — a 92.8% reduction and 74.4% token savings. Every model could load and use it. Task completion on GPT-4o went from impossible to functional.
Our recommendation: If your OpenAPI spec has more than 50 operations, you need a bundling strategy before converting to MCP. Don't ship a 1:1 conversion. Note: bundling introduces a routing layer that can occasionally misroute requests — in our testing, execution success dipped from 100% to 89% with bundling, but task completion improved from 55% to 81%. The tradeoff is almost always worth it, but test after bundling to catch regressions.
Bundling strategies that work
We tested two approaches:
Tag-based bundling groups operations by their OpenAPI tag. GET /repos/{owner}/{repo}, GET /repos/{owner}/{repo}/branches, POST /repos/{owner}/{repo}/forks all become methods on a single repositories tool. This is the simplest approach and produced the best results in our testing — 41 tools from 570 operations.
Path-based bundling groups operations by URL path prefix. /repos/* operations become one tool, /issues/* become another. Similar results, slightly less semantic coherence because path structure doesn't always match logical grouping.
Both approaches dramatically outperform unbundled conversion. The choice between them depends on how well your OpenAPI tags reflect logical groupings.
// finding 03
Why do OpenAPI descriptions fail for AI agents?
OpenAPI operation descriptions are written for human developers reading API documentation. They say things like:
"Lists repositories for the specified organization. Note: In order to see the
security_and_analysisobject, you must be an organization owner with GitHub Advanced Security enabled."
An agent reading this doesn't know when to choose this tool. The description tells it what the endpoint does technically, but not what task shape it serves. Is this for browsing code? Finding a specific repo? Auditing permissions?
In our testing, raw OpenAPI descriptions produced 77% task completion on GPT-4o. After rewriting descriptions to signal task shapes and expected inputs:
- Task completion rose to near-100% on GPT-4o
- Models sent better parameters (more specific queries, correct use of optional filters)
- Selection rates improved in competitive scenarios
The rewrite isn't cosmetic. It's the difference between the agent understanding when your tool is the right choice versus treating it as one of 40 interchangeable options.
What a good converted description looks like
Before (raw OpenAPI):
"List organization repositories. Lists repositories for the specified organization."
After (agent-optimized):
"List repositories in a GitHub organization. Use when someone asks about an org's projects, repos, or codebase. Accepts org name as a natural string. Returns repo names, descriptions, languages, and stars. Use the 'sort' parameter for 'stars', 'updated', or 'created' to find popular, recent, or oldest repos."
The rewrite adds: task shapes it serves, what natural-language inputs it accepts, what the response contains, and when to use optional parameters.
// finding 04
How should you write parameter descriptions for AI agents?
OpenAPI parameters are documented for developers who read docs. Agent-facing parameters need to be self-documenting:
Before:
{
"name": "per_page",
"type": "integer",
"description": "The number of results per page (max 100)."
}
After:
{
"name": "per_page",
"type": "integer",
"description": "Number of results to return, 1-100. Default 30. Use 100 for comprehensive listings, 5-10 for quick lookups."
}
The difference: the "after" version tells the agent how to choose a value, not just what values are technically valid. In our corpus, optional parameters with minimal descriptions had near-zero utilization rates — agents ignored them entirely. When descriptions included usage guidance, utilization increased and task completion improved by 11 percentage points.
// finding 05
How should MCP servers handle API authentication?
OpenAPI specs define auth schemes (OAuth2, API key, Bearer token). MCP servers need to handle auth at the transport layer — the agent shouldn't be constructing Authorization headers.
The common failure: converting an API that requires authentication but not handling it in the MCP server wrapper. The agent sends a valid tool call, the server forwards it without auth, the API returns 401, and the agent has no way to fix it.
In our testing, auth-related failures (HTTP 401, 403) accounted for a significant share of execution failures — particularly on APIs with tiered access where some endpoints require paid plans. The agent has no way to know which endpoints are free and which are paywalled unless the tool description says so.
The fix: Handle auth in the server. Document tier restrictions in tool descriptions. If an endpoint requires a Pro subscription, say so — "Requires Pro API access. Returns 401 on free tier." The agent can't fix auth problems, but it can avoid endpoints it knows will fail.
// finding 06
Does API response format affect agent task completion?
OpenAPI specs define response schemas but don't control how the data is formatted for agent consumption. A raw API response might be a 50KB JSON blob with nested objects, pagination metadata, rate limit headers, and deprecated fields mixed with current data.
The agent receives this entire payload and has to extract the answer. Larger payloads consume more tokens and increase the chance of the agent missing or misinterpreting the relevant data.
In our testing, utility — whether the API response was actually useful to the agent — varied significantly by how responses were structured. APIs that returned focused, well-labeled data had near-100% utility. APIs that returned large, noisy payloads had lower utility rates, particularly on budget models with smaller context windows.
The practical approach: Your MCP server wrapper should filter and format API responses before returning them to the agent. Strip pagination metadata, remove deprecated fields, flatten unnecessary nesting, and label ambiguous fields (e.g., rename price to price_usd_current).
// finding 07
The conversion pipeline
Based on our experience building and testing the OpenAPI-to-MCP pipeline, here's the sequence that works:
Step 1: Filter operations. Start with read-only operations unless write access is specifically needed. Our pipeline reduced GitHub from 1,087 to 570 operations in this step alone.
Step 2: Bundle. Group by OpenAPI tag or path prefix. Target 20-50 tools. Our testing shows this range gives models enough specificity to select correctly without overwhelming the tool surface.
Step 3: Rewrite descriptions. For each bundled tool, write a description that signals: what task shapes it serves, what inputs it accepts in natural language, what the response contains, and when to use optional parameters.
Step 4: Translate parameters. Add usage guidance to parameter descriptions. Flag required vs. optional with behavioral guidance, not just schema annotations.
Step 5: Handle auth and response formatting. Auth at the transport layer. Filter and label responses.
Step 6: Test across models. This is the step most publishers skip. A surface that works on Claude may fail on GPT-5.4 (128-tool cap) or get ignored on Gemini (higher refusal rates). Test with at least 2-3 models before shipping.
// finding 08
What the data shows
From our OpenAPI pipeline testing (294 observations across 4 models):
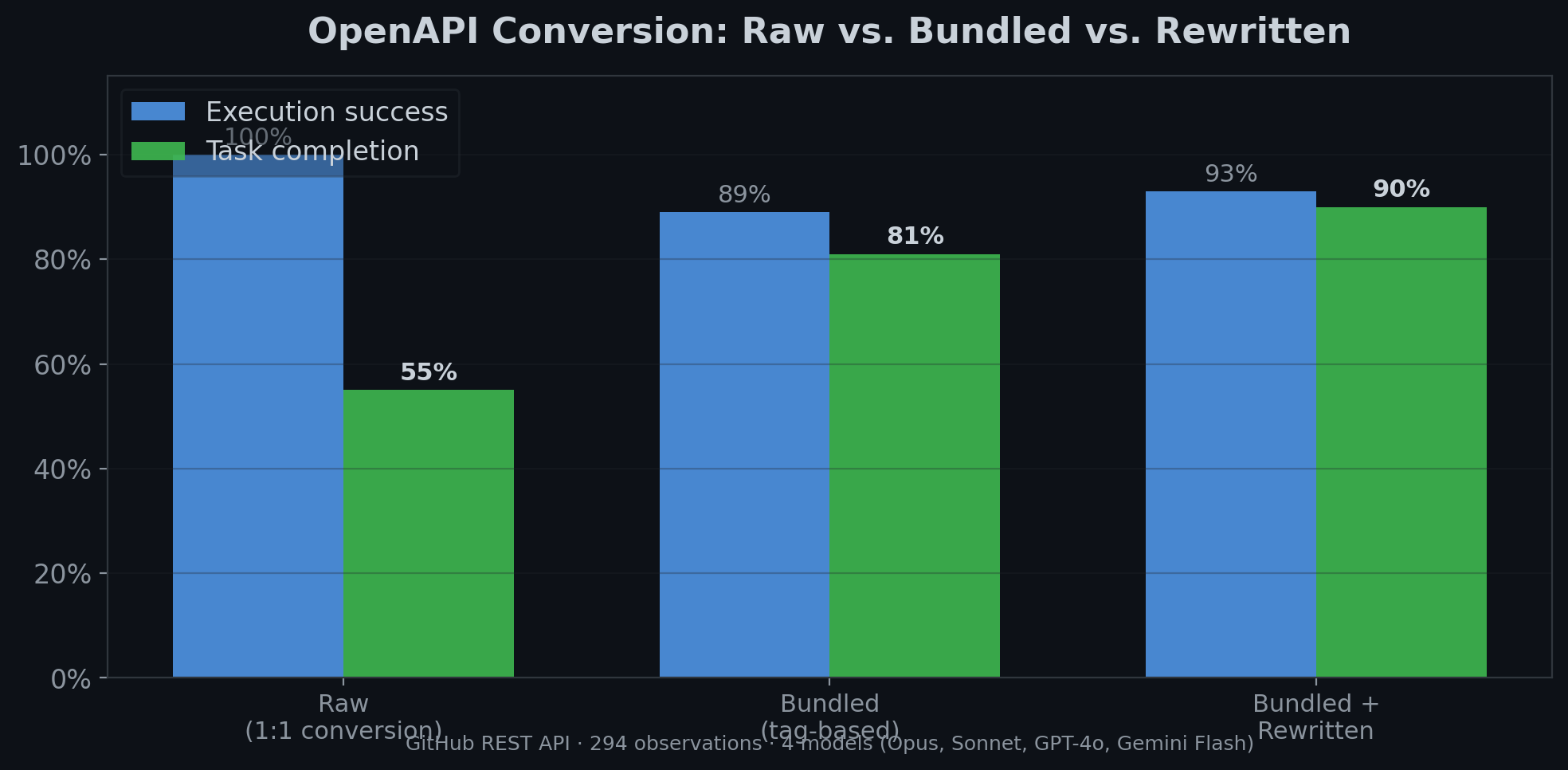
| Surface variant | Task completion | execution success |
|---|---|---|
| Raw (1:1 conversion) | 55% | 100% |
| Bundled (tag-based) | 81% | 89% |
| Bundled + rewritten | 90% | 93% |
The raw conversion works mechanically — execution success is 100% because the API calls go through fine. But task completion is only 55% because models send suboptimal parameters and misunderstand when to use which tool. Bundling lifts task completion to 81%. Rewriting descriptions on top of bundling pushes it to 90%.
The execution success dip on bundled surfaces (89% vs 100%) reflects the bundling layer adding a routing step that occasionally mismatches. This is a known tradeoff — you trade a small execution risk for dramatically better selection and task completion.
// appendix
Methodology and disclosure
OpenAPI pipeline results are based on 294 observations across Claude Opus, Claude Sonnet, GPT-4o, and Gemini Flash, tested against the GitHub REST API converted through three surface variants (raw, bundled, bundled_rewritten). Tool count and token measurements are from our pipeline's presentability analysis. All testing used free-tier API access.
Results reflect observed behavior during controlled testing. Conversion outcomes depend on the specific API, its OpenAPI spec quality, bundling strategy, and the models used. The GitHub API was chosen for testing because of its size and complexity — smaller APIs may need less optimization.
Want to see how your OpenAPI spec looks to agents? Run a free Agent Readiness Scan →
Want this run against your own tools?
We test your endpoints live across multiple models and deliver a report with specific, ship-ready fixes.
Book an audit →