How LLMs Choose Which Tool to Call (And Why Yours Gets Ignored)
When an AI agent has access to multiple tools, how does it decide which one to use? We ran 4,914 real tests across 5 models and 5 verticals to find out. The answers are specific, measurable, and often counterintuitive.
When you give an LLM access to tools — MCP servers (standardized tool servers that let AI agents discover and call your API), function calls, API connectors — it doesn't just pick the first one it sees. It makes a decision. And that decision is remarkably consistent, remarkably patterned, and remarkably fixable when it goes wrong.
We know this because we tested it. Not with synthetic benchmarks or hypothetical scenarios, but by sending real prompts to real models (Claude, GPT-4o, GPT-5.4, Gemini Pro, Gemini Flash) with real competing tools loaded simultaneously, then measuring which tool got chosen and whether it actually worked.
4,914 observations. Five models from three providers. Five verticals (search, weather, crypto, dev tools, OpenAPI). Controlled experiments with tool ordering randomized to eliminate position bias.
Here's what we found.
- ▸Task-shape matching is the #1 driver of tool selection — specific descriptions ("search for local businesses near a location") beat generic ones ("search the web") by wide margins
- ▸Bundled tools outperform many narrow tools — 39 bundled tools received 85% of selections vs 7% for 100 individual tools in a head-to-head test
- ▸Your biggest competitor is the model's own training data — models skip tools entirely 13% of the time, rising to 43% on some model families
- ▸Brand doesn't matter — GitHub's selection rate dropped only 3 percentage points when anonymized
- ▸Description rewrites produce measurable lift — one rewrite took a tool from 0% to 34% selection share
// finding 01
What determines which tool an LLM selects?
The single strongest predictor of which tool gets chosen is whether the tool's description matches the shape of the user's task.
This sounds obvious. It isn't, because most tool publishers write descriptions that are either too generic ("search the web") or too technical ("execute a paginated query against the index with optional facet parameters"). Neither tells the model when this tool is the right choice.
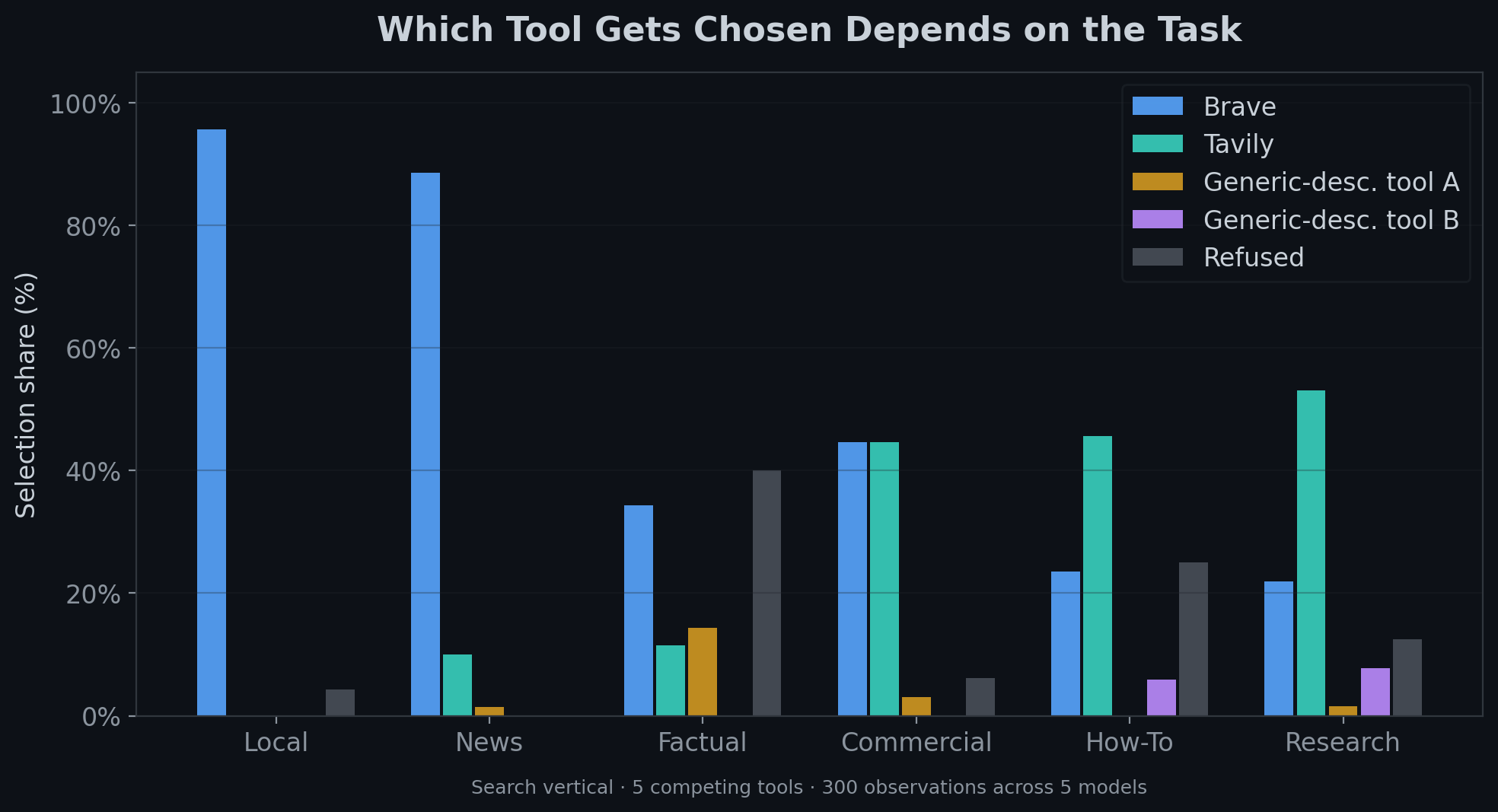
Look at the search vertical. Five competing tools, same prompts, same models. Brave Search received 94% of local and news queries in our testing — its dedicated brave_local_search and brave_web_search tools have descriptions that signal exactly those task shapes. Tavily received the majority of research and commercial queries, with descriptions that emphasize depth and synthesis.
Two competing search tools with broad, generic descriptions received roughly 3% and 0.2% of selections respectively across 300 observations in this configuration. Their descriptions at the time of testing were more generic — a broad "search the web" description competes poorly against a specific "search for local businesses and places near a location" when both are available simultaneously.
The takeaway: Models don't read your description and think "this seems good." They pattern-match: does this tool's stated capability align with what the user just asked? The more specifically your description matches real task shapes, the more often you win.
// finding 02
How many tools should an MCP server expose?
There's a sweet spot in tool architecture.
A single generic tool ("do everything") loses to tools that signal specific capabilities. But fragmenting your API into dozens of narrow tools creates a different problem: the model has to scan through all of them, and the cognitive load (measured in tokens) means your tools compete with each other.
The data:
- A method-bundled server (39 bundled tools): Received 85% of selections when tested head-to-head against a 100-tool server and a 45-tool server. The method-bundled design — one tool handles multiple related operations — gives the model clear, distinct capabilities without overwhelming the tool surface.
- A one-tool-per-operation server (100 individual tools): Received 7% of selections in the same test. With one tool per API operation, the model sees 100 options and routes most queries to the server with a more navigable surface. (Note: this reflects that server's default MCP architecture, not the quality of the underlying API itself.)
- The extreme case: When we combined all three dev tools servers (184 total tools), GPT-5.4 rejected the entire request. It has a hard cap at 128 tools — inherited from GPT-4o and unchanged across model generations as of early 2026. Your tool architecture directly determines model compatibility.
We confirmed this with a controlled experiment on the GitHub API: the original 570-operation surface was invisible to GPT-4o. After bundling to 41 tools — a 92.8% reduction and 74.4% token savings — GPT-4o could load and use it perfectly. Same API, same capabilities. Different architecture, completely different outcome.
// finding 03
Why do LLMs ignore available tools and answer from memory?
Here's a finding that surprised us.
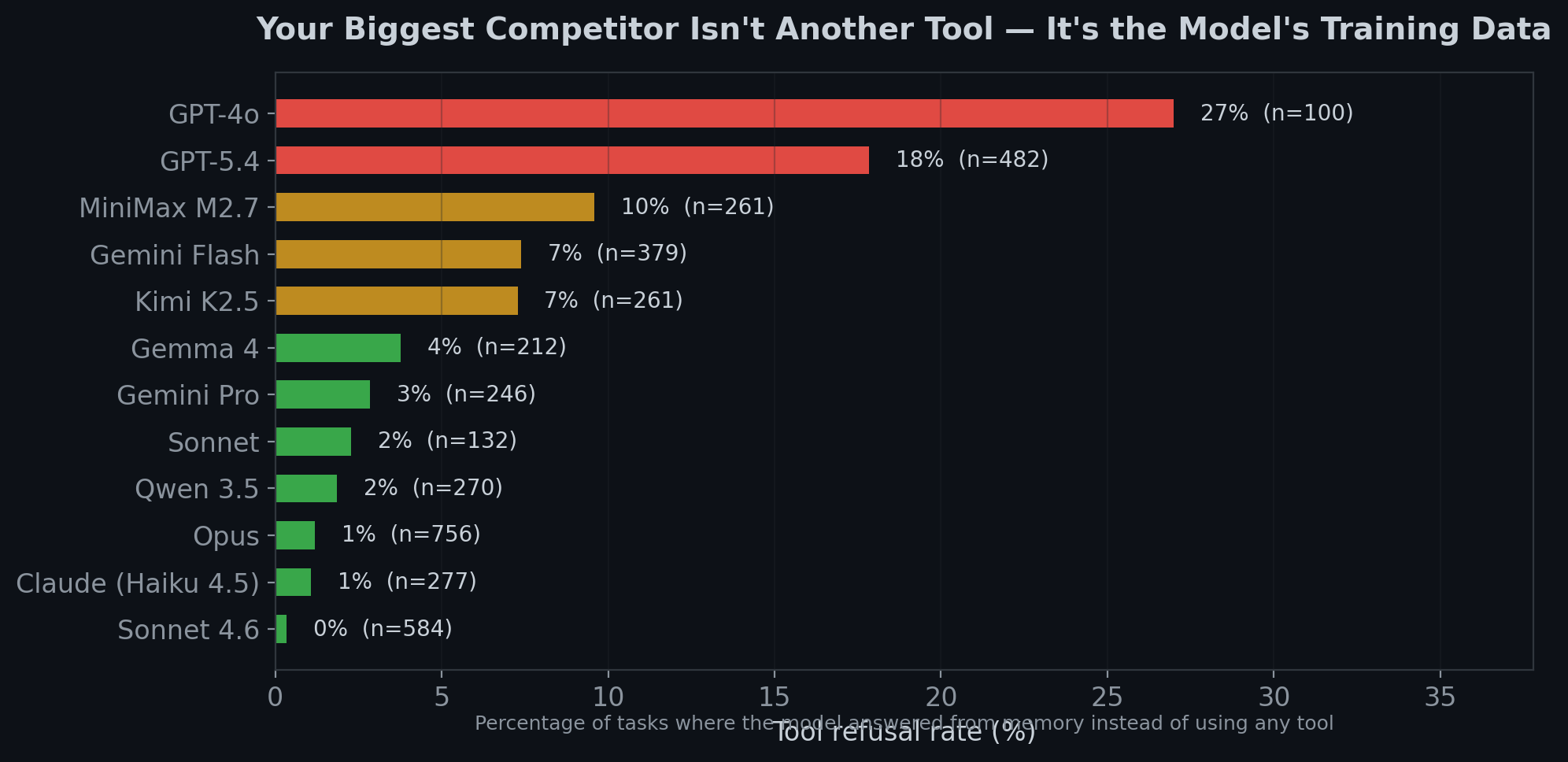
Across all our testing, 13% of tasks resulted in the model ignoring every available tool and answering from its own training data instead. The model decided it already knew the answer and didn't need your API.
This varies dramatically by model family. The chart below shows cross-vertical refusal rates from our full corpus. Rates vary significantly by vertical — in search specifically, OpenAI model refusal was higher and worsened across generations (GPT-4o 37%, GPT-5.4 43%). Anthropic's Claude models had the lowest refusal rates across all verticals.
This is not a bug. It's the model making a cost-benefit calculation: "Is calling this tool worth the latency and token cost, or do I already know enough to answer?" When models are confident in their training data, tools lose.
What this means for tool publishers: Your tool description needs to signal "I have data you don't." Real-time data, private data, fresh data, authoritative data. If the model can plausibly answer from what it learned during training, it will — especially on OpenAI models. The phrase "real-time" or "live data" in your description is a competitive advantage against the model's own memory.
We tested whether you could force models to use tools by adding aggressive system prompts ("you MUST use tools for every query"). On one Gemini model variant we tested, this made refusal worse — from 31% to 50%. The aggressive instruction crowded out the tool descriptions. This appears to be a model-level trait, not a prompt-engineering problem.
// finding 04
Does brand recognition affect LLM tool selection?
We ran a controlled experiment: the same tools presented with real names (GitHub, GitLab, Gitea) versus anonymized names (Server A, Server B, Server C). Same descriptions, same capabilities, just the names changed.
GitHub captured 75% of selections with its real name. With the anonymous name? 72%.
A 3-percentage-point difference on a 30-prompt test is noise. Brand recognition has negligible effect on LLM tool selection. The model isn't impressed that you're GitHub. It's choosing based on whether your tool description matches the task shape and whether your architecture makes the tool surface navigable.
This is liberating if you're a smaller publisher: you don't need brand equity to win tool selection. You need a clear description and the right tool architecture.
// finding 05
Do tool description rewrites actually improve selection rates?
This is the most commercially important finding. Tool descriptions are changeable, and changes produce measurable results.
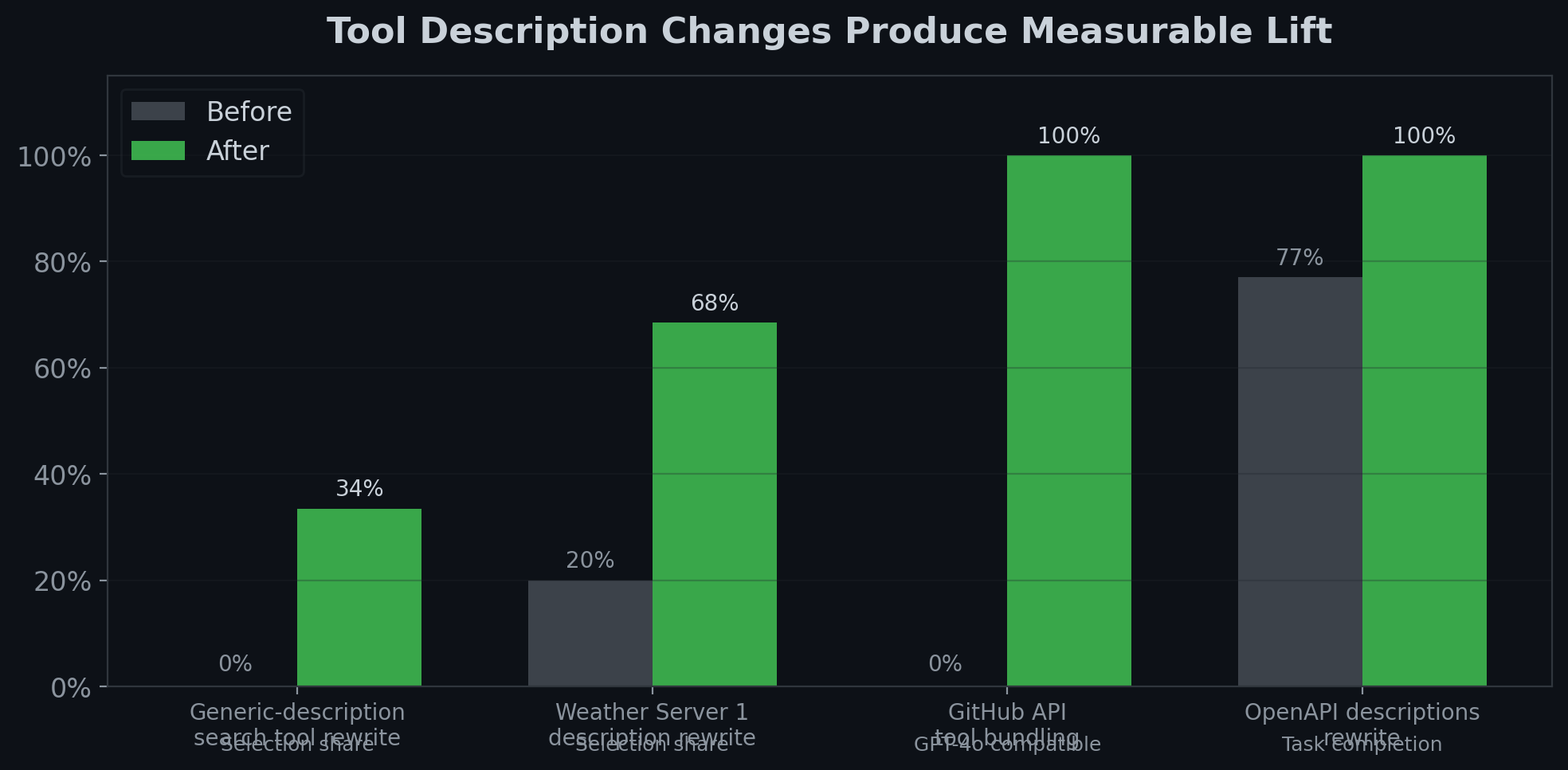
Four interventions, all producing significant lift:
- A generic-description search tool rewrite: Selection share went from 0% to 34% in our testing. The original description at the time was broadly worded; after rewriting to signal specific task shapes (instant answers, content extraction), models began routing queries to it. This reflects the description we tested, not any current production configuration.
- Weather server description rewrite: A weather API's selection share went from 20% to 68% after consolidating tools and rewriting descriptions to signal city-name inputs and specific weather data types.
- GitHub API bundling: Went from 0% GPT-4o compatibility (570 tools exceeded the cap) to 100% (41 bundled tools). Same API. Architecturally compatible.
- OpenAPI description rewrite: GPT-4o task completion went from 77% to 100%. Better descriptions led to better parameter choices, which led to more useful API responses.
But here's the critical caveat: not every rewrite helps. Academic research (Hasan et al., 2026) found that augmenting tool descriptions improved task success by 5.85 percentage points on average — but caused regression in 16.67% of cases and increased execution steps by 67.46%. A rewrite that looks good to a human can perform worse for a model.
You can't just rewrite and hope. You have to test before and after, across multiple models, and check for regressions.
// finding 06
What happens after a tool gets selected?
A tool can win every selection contest and still fail in practice. In our crypto vertical testing, one API with a broad tool surface was selected for the majority of queries but had significantly lower execution success at the free access tier we tested — rate limits (HTTP 429) and tier-restricted endpoints (HTTP 401) caused a large share of calls to fail. A competing API with a narrower surface had much higher execution success but received far fewer selections.
This is the selection-usability gap, and it's largely invisible to publishers. You see the API calls in your logs. You don't see the calls that went to a competitor because the model preferred their description, or the calls that never happened because the model answered from training data instead.
// finding 07
What actually drives selection: the hierarchy
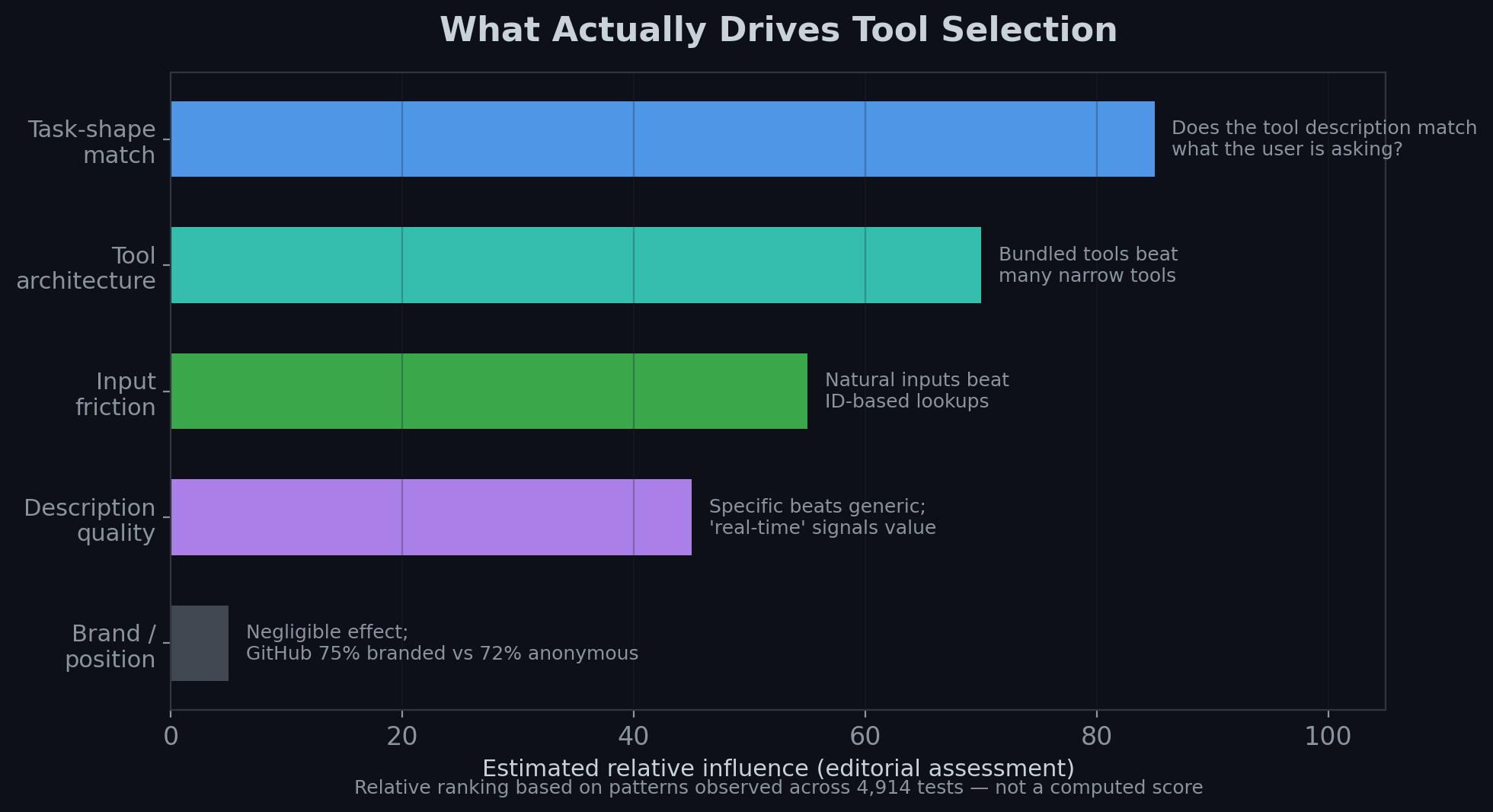
Based on patterns we observed across our full dataset, the factors that influence tool selection, in approximate order (this is an editorial ranking based on observed patterns, not a computed score):
- Task-shape match — Does your description signal the specific thing the user is trying to do? This is the dominant factor by a wide margin.
- Tool architecture — Bundled tools that each handle a distinct task shape outperform both single generic tools and many narrow tools. The sweet spot is 5-50 tools, each with clear purpose.
- Input friction — Tools that accept natural-language inputs (city names, ticker symbols, repo slugs) get chosen over tools requiring IDs, coordinates, or multi-step lookups. The model optimizes for the path of least resistance.
- Description quality — Specificity beats generality. Signaling real-time or private data beats generic capability claims. Including return value descriptions helps models judge fit.
- Brand and position — Negligible. Confirmed by controlled anonymization experiment.
// finding 08
What to do about it
If you publish tools for AI agents — MCP servers, function calling endpoints, API connectors — here's what the data says matters:
Check your task-shape coverage. What kinds of questions do users actually ask? Does each tool description clearly signal which task shape it serves? "Search the web" loses. "Search for local businesses and places near a location" wins.
Audit your tool count. In our testing, OpenAI models (GPT-4o and GPT-5.4) rejected tool surfaces exceeding 128 tools entirely. If you have more than 50, the token cost of your tool surface is competing with the actual conversation. Bundle related operations.
Signal what models can't know. "Real-time market data," "live weather conditions," "your private repository" — these phrases tell the model it can't answer from training data. Without them, you're competing against the model's own memory.
Accept natural-language inputs. Every parameter that requires an ID lookup is a friction point. If your API requires asset_id: "bitcoin" but doesn't accept name: "Bitcoin", the model has to make an extra discovery call before it can do useful work.
Test changes, don't just ship them. A rewrite that improves selection on Claude might cause regression on GPT-5.4. The only way to know is to test across models before and after.
// appendix
Methodology and disclosure
This analysis is based on 4,914 observations across Claude Sonnet 4.6, Claude Opus, GPT-4o, GPT-5.4, Gemini 3.1 Pro, and Gemini 3.0 Flash, tested against real production API endpoints with randomized tool ordering to control for position bias. The corpus includes data from both current and previous-generation models where applicable. All tools were tested in their default, publicly available configurations at the time of testing, using free-tier API access where applicable.
Results reflect observed model behavior during controlled testing and may not represent real-world usage patterns. Tool performance depends on configuration, API tier, model version, system prompt, and the specific tools available in a given session. Selection share percentages describe outcomes in our specific test configurations (all competing tools loaded simultaneously) — real-world environments typically have fewer tools present, which changes selection dynamics.
Where specific tools are named, the observations describe the tool definitions and API behavior we tested against, which may differ from current production configurations. No tool or API publisher was involved in or informed about this testing.
Model names (Claude, GPT, Gemini) refer to specific model versions available at the time of testing. Model behavior may change with updates.
Want to see what agents actually do with your tools? Run a free Agent Readiness Scan →
Want this run against your own tools?
We test your endpoints live across multiple models and deliver a report with specific, ship-ready fixes.
Book an audit →