Datadog MCP Server: Lessons Validated Across 17 Others
Datadog's engineering team published a field report from building a production MCP server. Their four interventions — JSON to CSV, token-budget pagination, SQL tools, actionable errors — match patterns we've measured across 17 MCP servers and 6,265 agent-tool interactions. Here's the broader picture their post fits into, where each lesson generalizes strongly, and where it's conditional.
Datadog's MCP post is the best field report we've read on what actually breaks when you expose APIs to agents. They did the hard thing — noticed agents failing in real use and iterated until they stopped failing — and then wrote the whole thing up publicly. That's a gift to everybody building in this space.
So rather than treat their post as something to be debunked or outdone, let's take it seriously and see how the patterns they hit on show up elsewhere.
- ▸Datadog's four interventions are real and reproducible. They show up across completely unrelated APIs — crypto, weather, devtools, search, observability. The pattern is the pattern.
- ▸Tool bundling cut GitHub's surface from 570 to 41 tools — task completion on GPT-4o went from 77% to 100%, and we got back under OpenAI's 128-tool cap. Matches Datadog's "fewer, flexible tools" finding dead-on.
- ▸Discovery guidance inside errors is measurable. On CoinCap, 0 of 16 slug-mismatch 404s had a prior discovery call. When the model did call the discovery endpoint first? Lookup succeeded 100% of the time. A single hint in the 404 body would close most of that gap.
- ▸Format and pagination choices matter — but the size of the win depends on data shape. CSV/TSV wins big on row-shaped tabular data. Token-budget pagination wins when records vary wildly in size. Both are strong within their fit, less magical outside it.
- ▸Datadog's real contribution isn't the four fixes — it's the loop. Watch agents fail, ship a fix, watch outcomes. Cross-server measurement tells you which specific lessons will land on your server without having to rediscover each one from scratch.
// finding 01
What did Datadog find when they built their MCP server?
Short version: they started by exposing their APIs as tools directly, watched agents lose track of objectives, blow token budgets, and fumble trend questions from raw samples — then iterated.
Their four main interventions:
- Response format optimization. Switched from JSON to CSV/TSV for tabular data. "About 5× more records in the same number of tokens" for some tools. YAML got them ~20% on nested stuff.
- Token-based pagination. Ditched record-count pagination for token-budget limits, because individual records varied from 100 characters to 1MB. Fixed-count pagination can't give predictable context cost under that kind of variance.
- Query-language support. Added SQL as a tool instead of only granular retrieval endpoints. Reported ~40% cheaper per answer in some scenarios.
- Guidance mechanisms. Specific error messages with suggestions. A documentation-search tool. Contextual hints in tool results. Agents recovered from errors more effectively.
They also did the thing every large OpenAPI surface needs eventually — replaced one-tool-per-endpoint with flexible multi-purpose tools, plus optional toolsets for specialized workflows.
It's a useful post. It confirms from inside a real production service that tools-for-agents is a distinct engineering discipline from APIs-for-developers.
The question it leaves open for everyone else: how much of this is Datadog-specific, and how much generalizes? That's what we've been measuring.
// finding 02
How do these findings generalize across other servers?
Quick framing note. Agent-readiness measurement — in the sense we use it — is the practice of testing whether real models, given realistic user prompts, can actually select, call, and complete tasks with a given tool surface. It's not API monitoring (that measures uptime). It's not LLM evaluation (that measures model capability). It measures the interaction between the two.
Our corpus: 6,265 observations, 17 validated servers, 10 models, spread across crypto, weather, search, devtools, and a couple of knowledge/reference verticals.
Here's what the data adds to each Datadog intervention.
Tool bundling: what it looks like across servers
Datadog's move to fewer, flexible tools is the most broadly applicable lesson in their post. In our data, it shows up clean on basically any large API surface.
Case in point: GitHub. We took its 570 raw OpenAPI operations and bundled them by resource category into 41 tools with a method parameter. Results:
- 92.8% tool-count reduction (570 → 41).
- 74.4% token savings on the tool-surface payload.
- Gained GPT-4o / GPT-5.4 compatibility. OpenAI caps tool surfaces at 128 tools. A 570-tool surface is rejected outright — the model never sees any of them.
- Task completion on GitHub went from 77% to 100% on GPT-4o after bundling + description rewrites.
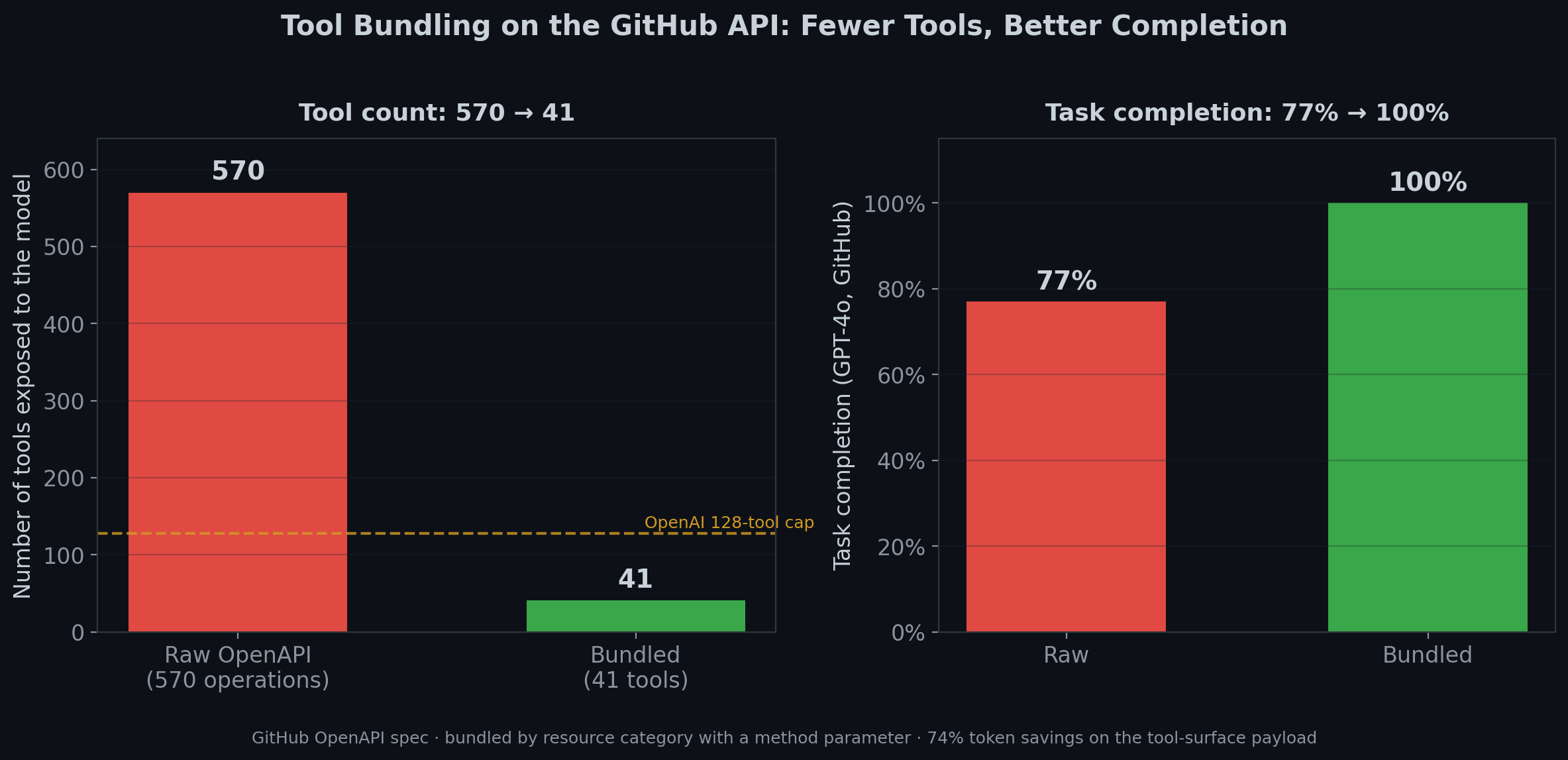
This matches Datadog's direction exactly. Fewer, flexible tools beat many narrow ones — both because of token economics and because models struggle to discriminate between near-identical endpoints. (Ask any human to pick between get_issues, list_issues, search_issues, and find_issues at 3am and see how that goes.)
One nuance worth adding though: over-bundling hurts. A single catch-all "do anything with issues" tool blurs the task-shape signal that helps models pick correctly. In our controlled rewrite tests, the best surfaces use a moderate number of tools where each one signals a specific task shape — which happens to be exactly where Datadog landed with their optional toolsets. Not "bundle everything." Not "one per endpoint." Somewhere sensible in the middle.
Error actionability: what the cross-server picture looks like
Datadog's fourth intervention — actionable errors, documentation search, contextual hints — is the one they emphasize most. We score every tool-call error in our corpus on a 0–2 actionability scale:
- Score 0 (opaque):
{"error": "not found"}or HTTP 429 with no body. - Score 1 (informative): the error explains what went wrong but suggests no recovery path.
- Score 2 (actionable):
{"error": "asset not found", "hint": "use /v3/assets?search=<name>"}or{"error": "rate limited", "retry_after_seconds": 60}.
Now here's the honest bit. A clean cross-server comparison of recovery rates by actionability is harder than it looks — server difficulty confounds the bucket. Servers whose errors are mostly opaque (hi CoinCap) also happen to have tasks the model can often fall back on from prior knowledge. Servers whose errors are mostly actionable (hi GitHub) tend to have harder tasks. Aggregate comparisons mix those effects.
Translation: we don't have a clean cross-industry number for "going from opaque errors to actionable errors gives you X% more recovery" — not yet. The only way to know how much an error-message change buys your server is to A/B test it on your server.
What we can show cleanly — and where Datadog's instinct is absolutely right — is the within-server mechanism. On CoinCap, 16 out of 16 slug-mismatch 404 failures happened when the model skipped the discovery endpoint (list_assets). When the model called list_assets first, the lookup succeeded 100% of the time. A single hint: "use list_assets to find valid IDs" in the 404 body would close most of that gap. One line. Not a redesign. Exactly the kind of fix Datadog describes baking into their own error paths.
When JSON → CSV delivers the 5× savings
Datadog's "about 5× more records in the same number of tokens" claim is real under their conditions. The mechanism is brutally obvious once you look at it — JSON's repeated field names are pure overhead on row-shaped data. Same payload, dumped as CSV, weighs a fraction as much.
We haven't run a controlled JSON → CSV test in our corpus yet (it's on the list). The direction is clearly right. The multiplier you'll actually get depends on shape.
Where 5× lands cleanly: large, row-shaped, mostly-flat result sets. Most observability and analytics APIs fit that description — which is why Datadog got the number they got. Where the savings collapse: deep-nested objects that don't flatten well, small result sets where tokens aren't the bottleneck, consumers that can't parse CSV reliably.
Rough heuristic: if you're shipping hundreds or thousands of rows at a time, this is free money. If you're returning one object with three fields, don't bother.
When token-budget pagination earns its keep
Datadog's record sizes vary from 100 characters to 1MB. Under that kind of variance, fixed-count pagination fails predictably — one page blows any reasonable context window, another page barely uses any of it. Token-budget pagination fixes that.
The catch: most REST APIs don't have that level of variance. If your records are roughly uniform in size, ?limit=50 is simpler, does the same job, and is what every model already knows how to use out of the box.
Where token-budget pagination is the right design: logs, documents, search results with embedded content, event streams. Anywhere payload size varies by orders of magnitude. Everywhere else, don't over-engineer it.
Where SQL tools pay off
Datadog's ~40% cheaper-per-answer claim is intuitive once you think about it. One SQL query can replace a chain of list / filter / aggregate round-trips. Fewer calls. Less data in context. More correct answers per token.
But this one has trade-offs that depend pretty heavily on who's writing the SQL.
Where it wins: Relational or analytical data with a well-defined schema, consumed by a capable model. This is exactly Datadog's case — observability data, logs-and-metrics-and-traces, models like Opus or Sonnet that can actually write decent SQL.
Where to tread carefully: Agent SQL-writing skill varies sharply by model. Smaller models write queries that silently return wrong answers. Schema complexity becomes a new surface for agents to misunderstand. And SQL tools are a fresh attack surface for untrusted input if your permissions aren't scoped tightly.
On a data-warehouse or observability API with a capable consumer, SQL is a clear win. On a simple REST API stitching together five business objects, a read-only SQL surface is more interface than you need. Match the tool to the data shape.
// finding 03
How to apply Datadog's lessons to your own server
Here's where it gets interesting. Datadog didn't arrive at these four fixes by reading a blog post. They arrived at them by running an iterate-and-measure loop internally — watched agents fail, formed hypotheses, shipped fixes, watched outcomes. That loop is the thing worth replicating.
And it matters, because not every well-intentioned rewrite actually helps. Hasan et al. studied MCP tool description rewrites — augmenting descriptions improved task success by 5.85 percentage points on average, but caused regression in 16.67% of cases. One in six rewrites made things worse. If you read a best-practices post and start rewriting descriptions without testing, you're flipping coins.
So the loop that worked for Datadog — and that Hasan's paper implies is necessary for anyone — is:
- Measure the current behavior of real agents against your tool surface, across multiple models.
- Hypothesize a change, pulling from work like theirs or ours.
- Retest under identical conditions.
- Ship only the changes that produce measurable lift. Revert the ones that regress.
Running this loop is straightforward when you own the server and the observability stack. It's much harder when you don't own the server, or you're trying to test across models you haven't instrumented, or you want an independent read instead of grading your own homework. That's the measurement category we work in.
// finding 04
What should MCP server builders do with this?
Reading list, roughly ordered by leverage:
- Audit your error messages first. Cheapest, highest-lift fix most APIs can ship. If your 404s and 429s return opaque bodies, the agent has no recovery path. Move every error your server returns from score 0 to score 2.
- Count your tools. More than ~50 tools, or one-per-endpoint from OpenAPI? You're burning context and risking the 128-tool cap on OpenAI models. Bundle by resource category, don't over-bundle to a single catch-all.
- Check input friction. If your tools require exact IDs, slugs, or coordinates, the agent makes prep calls before every real call. Accept natural-language inputs where you can (city names, ticker symbols). Where you can't, make the discovery endpoint impossible to miss — named in the description, referenced from the error body.
- Format optimization is for scale. CSV/TSV is a real win for multi-hundred-row responses. For small or nested results, not worth the complexity.
- Token-budget pagination is for variance. If your records vary by orders of magnitude in size, yes. Otherwise, count-based pagination is fine.
- Measure before you rewrite. The rewrites most likely to help are targeted at failure modes in your actual traffic, not lifted from a generic checklist.
// finding 05
The broader point
Datadog's post validates something we've believed from the first corpus run: tool-surface design for agents is a distinct engineering discipline from API design for developers, and the gap between "wrapped API" and "agent-ready tool" is measurable, repeatable, and large.
The MCP server best practices that generalize cleanly — bundled tools, actionable errors, scoped query surfaces, format matched to data shape — are already visible in the cross-server data.
The interventions Datadog describes show up as patterns across completely unrelated APIs in our data. The generalization is real. The lift is real. What their post doesn't focus on — and what most public writing on this topic still skips past — is the measurement side: how do you know which of these interventions will land on your server, with your data shape, before you ship it?
That's the part most teams still don't have a clean answer to. If you're building an agent-facing API and you want to see what agents actually do with it — before and after a change — run the free Agent Readiness Scan against your tool surface. Or book an audit for the full diagnostic.
Big thanks to the Datadog team for putting this work in public. More posts like theirs, please.
// appendix
Methodology and disclosure
Measurements are based on 6,265 observations across Claude Sonnet 4.6, Claude Opus, GPT-4o, GPT-5.4, Gemini 3.1 Pro, Gemini Flash, and other models, tested against real production API endpoints. Tool bundling results are from controlled A/B testing on GitHub's OpenAPI surface. Error actionability figures are corpus-wide and confounded by server difficulty — cited here only where that confounding is disclosed. CoinCap discovery-endpoint data is single-server and scoped accordingly. Third-party figures (Hasan et al., Datadog) are cited to their sources.
Results reflect observed model behavior during controlled testing and may not represent real-world usage patterns. The MCP ecosystem evolves rapidly.
tracingviolet measures how AI agents select and use agent-facing APIs. Full public findings and schema at tracingviolet.dev.
Want this run against your own tools?
We test your endpoints live across multiple models and deliver a report with specific, ship-ready fixes.
Book an audit →